

データサイエンスグループの社員が「ネットワーク分析を利用したRWD(リアルワールドデータ)解析の概要と手法」について解説してみた

本記事は中外製薬 デジタル戦略推進部 データサイエンスグループの岡田が執筆を担当しました。
自己紹介
こんにちは、デジタル戦略推進部データサイエンスグループの岡田法大です。私は入社以来、生物統計の担当者として臨床試験の解析を行っており、その一環として、医薬品開発や市場調査におけるリアルワールドデータ(RWD)の有効な活用方法の検討も行っています。「製薬会社でデータサイエンスってどんなことをやっているの?」という皆さまに向けて、RWDの活用に向けたネットワーク分析の概要と手法、RWDを扱う上での課題や展望を紹介したいと思います。
RWD(リアルワールドデータ)とは何か
まず最初に、RWDとは何か?を解説します。RWDとは、日常の実臨床の中で得られる医療データの総称です。RWDにはレセプトデータ、DPC(Diagnosis Procedure Combination)データ、電子カルテのデータ、健診データ、患者レジストリデータ、ウェラブルデバイスから得られるデータなどがあります。
その中でも、レセプトデータとDPCデータは厚生労働省のNDB(National Database)や、PMDA(医薬品医療機器総合機構)のMID-NET(Medical Information Database Network)を構成するデータとしても広く利用され始めており、中外製薬でも現時点で最も利用されているRWDの一つです。レセプトデータとDPCデータには実際に行われた診療の情報が患者単位で含まれているため、薬剤の市場調査に加えて、薬剤を使用した患者さんの情報(利用した医療機関や来院頻度)や、薬剤の使用状況(投与量や投与頻度)を確認することが可能となります。
RWDから薬剤の使用状況を分析するには
一人ひとりの患者さんの治療経過を俯瞰することや、データの中の薬剤の使用人数の集計を行うことは容易ですが、症状が多岐に渡る疾患での薬剤の使用状況や、適応症の多い薬剤の使用状況の調査を行う際には、データに含まれるすべての患者さんの情報を確認して、使用状況の分布を確認する必要があります。解析の担当者は、薬剤がどのような特徴を持った患者さんに、どのような状況で使用されているのかを明らかにするために、大量の患者さんのデータから傾向を把握するデータマイニングの作業に注力しています。
ネットワーク分析を利用した解析の概要と展望
レセプトデータやDPCデータの解析では、解決したい課題によって、時系列情報を用いたり、因子分析を行ったり、様々な解析のアプローチが考えられます。今回は、解析の一例として、薬剤がどのような状況で使用されたかを調査するために、他の薬剤や処置との併用関連から薬剤使用時の患者さんの状況を推定するために「ネットワーク分析」を利用した解析を紹介します。
Twitterのフォローとフォロワーの関係からみてみる
ネットワーク分析とは、様々なものの間の関連性を表現するときに用いられる解析方法で、事象をノードと呼ばれる頂点と、エッジと呼ばれる辺で構成されるグラフで表現します。ネットワークの作成方法は様々あり、例えばTwitterのフォローとフォロワーの関連を調査したいの場合は、ノードをアカウント、エッジをフォロー関係でネットワークを構築することが出来ます。調査内容によって、関連の方向を考慮するか否か(無向グラフ・有向グラフ)、関連の深さを考慮するか否か(重み付きグラフ)を選択することも出来ます。

レセプトデータの中にも、併発疾患や併用薬剤など関連性が重要となる情報が含まれており、疾患の全体像を俯瞰的に表現するためにはネットワーク分析はとても有効な方法となります。
薬剤・治療・合併症のネットワーク可視化の例
例えば、併用されている薬剤と治療に関して、薬剤と治療をノード、併用関係をエッジとして、併用人数をエッジの重さ(太さ)としたネットワークを作成してみます。以下に示す図は今回の説明のために簡易的に用意したもので実際の医療実態とは異なることをご容赦ください。
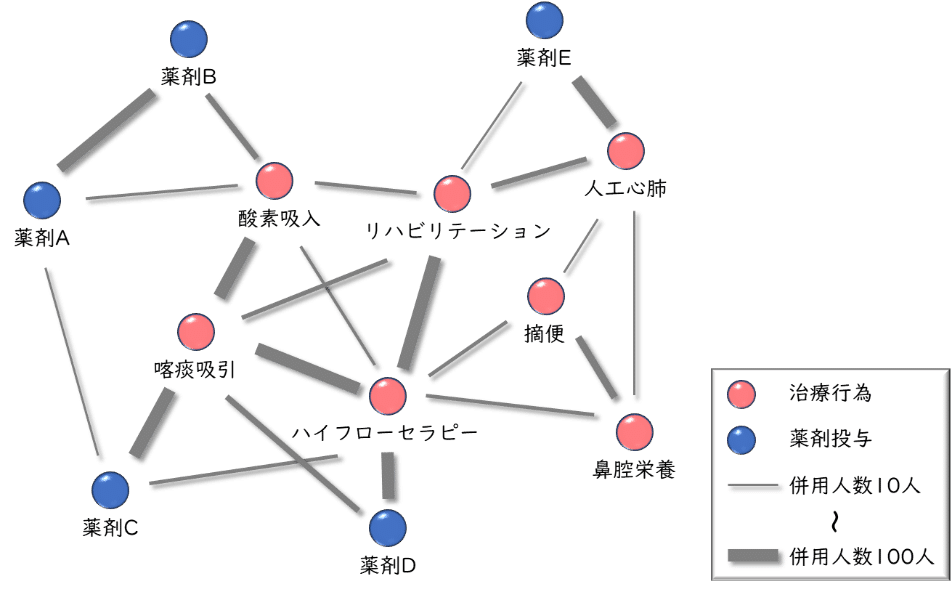
このように特定の疾患でネットワークを作成すると、各薬剤の使用実態を可視化することができます。図の例ですと、薬剤Aと薬剤Bは多くの場合併用で利用されていることや、薬剤Cと薬剤Dの使い分けにはネットワークに含まれていない因子が影響しているのか、又は競合しているのかのどちらかであることが想像されます。通常は、薬剤の選択は疾患の重症度やバイオマーカーに依存して行われることが多いため、それらの要因によるコミュニティが大きく形成されます。その次に各薬剤の特徴が表現できることが多く、合併症と相関のあるコミュニティが構成される疾患や、年齢などの背景情報と相関のあるコミュニティが構成される疾患など、各疾患の治療実態の特徴を確認することが出来るようになります。
ネットワーク分析のメリット
可視化以外にもネットワーク分析を用いる利点は多く存在します。何らかの関連性を利用して作成されたネットワークでは、関連が大きいノード群の間には密なネットワークが構成され、関連が小さいノードとの間には疎のネットワークが構成されます。このようなネットワークの特徴を利用して、モジュラリティという指標を利用したクラスタリング手法や、ノードやネットワークの特徴を分散表現に変換する表現学習も多く研究されています。これらの手法を用いることにより、今回作成したネットワークでのノード(薬剤と治療)をクラスタリングしたり、ノード間の類似度を計算することが可能となります。競合品目との使用状況の類似度を計算したり、治療方針ごとに形成されるコミュニティに含まれる患者さんの予後を確認することにより、アンメット・メディカル・ニーズの特定にも繋がると考えられます。ネットワーク分析の中でも解析方法は多様ですので、どれほど離れたノードとの関連性も各ノードの特徴として表現すべきかなど、解決したい問題に応じて適切な解析方法の選択が可能です。
多層のネットワークで患者さんの治療経過を表現
将来的には、患者さんの治療経過を、治療行為、薬剤、診断病名などからなる多層の有向グラフで時系列に表現することにより、疾患ごとの治療方針の体系化を目指しています。レセプトデータやDPCデータに記録されている、これまで実際に行われてきた治療方針や治療経過を定量的に表現できるようになれば、よりアンメット・メディカル・ニーズの特定や医療の均質化につながると考えています。

解析の課題
先にご説明した目標を達成するためには、各患者さんのバイオマーカーや予後の情報もとても重要となってきますが、実際には、レセプトデータとDPCデータには行われた診療の情報のみで、検査の結果や予後の情報は含まれていません。例えば、図4の「軽症患者」「中等症患者」「重症患者」というコミュニティのラベル付けには検査等の結果が必要になることが多く、現状ではラベル付けが困難な場面も多いです。昨今、このような課題を解決するために、疾患特有の検査結果や所見が含まれる疾患レジストリの構築や電子カルテデータなどの情報を研究に利用に関する議論も活発になっています。解析技術で解決出来る課題と、新たなデータの構築やデータの利用環境の整備が必要な課題を切り分けて、より正確で有用な情報を提供できるような仕組みを多面的に検討していきます。
岡田 法大(デジタル戦略推進部 データサイエンスグループ)