

【技術ブログ】データサイエンティストが解説!GeminiのFine-tuning方法の解説とMed-LM

こんにちは、中外製薬のデジタル戦略推進部で、データサイエンティストとして機械学習モデルの開発や導入をリードしている徳山です。前回は、AIによるデジタルパソロジーの取り組み事例を紹介しましたが、今回は最近話題の 大規模自然言語モデル (Large Language Model、以降、LLM) の取り組みについて紹介します。
徳山の過去のブログはこちら
大規模自然言語モデル(LLM)とは
大規模自然言語モデル(LLM)とは、膨大な量のテキストデータから、単語や文章の意味や文法を学習し、さまざまな自然言語処理タスクにおいて高い性能を発揮する深層ニューラルネットワークのことです。例えば、BERTやGPTなどが有名です。これらのモデルは、事前に一般的なテキストデータで学習された後、特定のタスクに合わせて微調整することで、質問応答、文章生成、機械翻訳、要約、感情分析など、幅広い自然言語処理タスクに対応できます。また、大規模自然言語モデルは、人間の言語知識や常識知識、事実知識なども暗に学習しており、自然な会話や推論なども可能です。
製薬・ヘルスケア領域では、創薬研究からヘルスケアソリューションに至るまで様々な技術開発が日進月歩で進んでいます。例えば、創薬研究においては化合物の情報を扱うことが可能なモデル開発や、病理画像の解析をテキストプロンプトで実行可能なマルチモーダル大規模言語モデルの開発などが論文報告されています。ヘルスケア領域では、医療現場に向けたLLM導入に向けて、様々な企業が医療情報を学習させた大規模言語モデルの開発に取り組んでいます。医療現場では、これらのLLMを用いて医療関連文書の作成などから業務効率化を進めることで、医師の働き方改革に向けた取り組みが進んでいます。
中外製薬におけるLLMの活用環境
中外製薬におけるLLMの活用環境について紹介します。
1. 業務内容に合わせ適切なLLMサービスを選択、切り替えることができる
中外製薬では高度なセキュリティ基盤を備えた全社共通のマルチクラウド環境として CCI(Chugai Cloud Infrastructure)を構築し、利用しています 。CCIでは、Microsoft Azure、Amazon Web Service (AWS)、Google Cloudの3つのクラウドサービスを利用することがき、中外製薬グループに所属する社員であれば、それぞれのクラウド上で利用可能なLLMやLLM関連サービスをすべて好きに選んで使うことができます。例えば、Microsoft Azureでは OpenAI社の開発するGPT-4 が利用でき、AWSではAmazon BedrockやAmazon Kendra、Google CloudではVertexAI上でGeminiなどが使えます。それぞれのLLM間で応答速度や回答精度などが異なるため、社員ユーザーが各々のタスクに合った好みのLLMを見つけ、業務に活用することを推奨しています。また、各クラウドベンダーの提供するモデルのバージョンのアップデートに併せて、すぐに社内へ提供を行うことで、最新のLLMを業務に用いることも容易となっています。
こちらが、現在社内で利用可能なLLM関連サービスとその特徴です。
Chugai AI Assistant:全社員向けのLLMチャットシステムとして利用。様々なLLMを呼び出すことが可能
Azure OpenAI Studio (Microsoft Azure) :GPT-4oなどOpenAI製LLMの利用
Amazon Bedrock / Kendra (AWS) Claude 3.5 SonnetなどAnthrophic製LLMの利用や、Kendraを用いたRAGサービスの利用
VertexAI (Google Cloud) GeminiやMed-LMなどGoogle製LLMの利用や、VertexAI AgentなどRAGやAgentサービスの利用
2. チャットアプリの内製開発により、ユーザーの利便性を向上
データサイエンティストとアプリ開発担当(tech工房)が協働し、中外製薬グループ全社員向けのLLMチャットアプリを内製開発し、社内提供を進めています。
本アプリケーション上では、各クラウドから提供されているLLMをユーザーが好きに選んで使う事ができます。

3.新規技術やサービスへの対応の速さは、内製開発ならでは
私たちは基盤技術の開発チームと連携しながら、アジャイル開発の手法を取り入れています。次々と開発、発表される生成AIやLLM関連サービスの情報をいち早くキャッチし、社内展開に向けた検討や評価を迅速に行い、RAG機能の導入やUI/UXの継続的な改善を行っています。
4.RAGやFine-tuningによる社内データでのカスタマイズ
一般提供されているLLMでは、ウィキペディアやWebクローリング (Common CrawlやRefinedWeb) などのテキストデータを事前学習用のデータセットとして学習されており、一般的なデータソースに含まれないような特定の情報に対する回答精度が低い場合があります。例えば、法律や規制・ガイドラインに基づいた回答生成や社内文章に基づいた回答生成を行おうとした場合、既存のモデルでは高い回答精度が得られません。
そこで、RAG (Retrieval Augmented Generation, 検索拡張生成) やファインチューニングを活用することで、社内データや任意のデータソースでLLMをカスタマイズし、特定の情報に対する回答精度を向上させることができます。大まかな構成図は図Xの通りです。RAGはAWSの提供するAmazon KendraやGoogle CloudのVertexAI Searchを用いることで、検索対象のファイルを用意すれば、検索用のデータベースの作成からクエリ検索までを簡単に実装することができます。

LLMだけの場合:
プロンプト:肺がんとその治療について教えてください
➡ “プロンプト”のみを入力として、LLMが回答する。
RAGによる検索拡張
プロンプト:肺がんとその治療について教えてください
+クエリ結果:
(Wikipedia) 一般的な症状は、血痰、慢性的な激しい咳、喘鳴(ぜんめい)、胸痛、体重減…
(Academic publication) Lung cancer is made up of distinct subtypes, including non–small-cell lung cancer (NSCLC) and small-cell lung cancer (SCLC)…
➡ “プロンプト+クエリ結果” を入力として、LLMが回答する。

GeminiのFine-tuningをやってみよう (ござるGeminiを作る)
2024年7月時点で、Google Cloud上では、Gemini 1.0-ProモデルのFine-tuningが実行できます。ここでは、databricks-dolly-15k-ja-gozaruのデータセットを用いて、GeminiのFine-tuningの実装コードを解説します。
1. ファインチューニング用データセットの用意
Huggingfaceの提供する`datasets`ライブラリを用いて、` databricks-dolly-15k-ja-gozaru` をダウンロードします。
import datasets
import pandas as pd
import json
dataset = datasets.load_dataset("bbz662bbz/databricks-dolly-15k-ja-gozaru")上位5件のデータを見ておきましょう。
gozaru_df = dataset["train"].to_pandas()
gozaru_df.head()
databricks-dolly-15k-ja-gozaruでは、instruction + input (closed_qaの場合のみ) を入力として、outputを出力とするデータセットが提供されています。特徴としては、outputの語尾がすべて “ござる” 口調になっているというデータセットです。本データを用いることで、ござる口調のGeminiが作れるでござる。さて、今回は簡単のためinstructionとoutputのペアのデータセットのみを用いてデータセットを準備します。
df = gozaru_df.loc[gozaru_df['input']=="",]GeminiのFine-tuning用のデータセットは下記の要件を満たす必要があります。
- JSON Lines(JSONL)形式で、各行に指定フォーマットで1 つのチューニング サンプルを含む必要がある
- 学習用データセットは500~1000件以上が望ましい
- 評価用データセットは256データ点数まで
JSONLファイルの各行のJSONフォーマットは下記の通りとなってます。
{
"messages": [
{
"role": "system",
"content": "You should classify the text into one of the following classes: [business, entertainment]"
},
{
"role": "user",
"content": "Diversify your investment portfolio"
},
{
"role": "model",
"content": "business"
}
]
}
フォーマットは見てわかる通り、Hugging faceのTRLライブラリのSFTTrainer とほぼ同様です (roleのassistantがmodelとなっただけです)。下記に解説をまとめます。
roleはsystem, user, modelのいずれかを指定する必要があります。
system(省略可) : モデルがどのように応答すべきかを指示。モデルにタスクの文脈を理解させ、カスタマイズされた応答を提供し、特定のガイドラインに従うことを可能にします。
user : ユーザーの入力するテキスト
model : モデルに出力させたいテキスト
messagesは最大32,768トークンまで、modelフィールド中のcontentは最大8,192トークンまで可能です。
念のため、トークンサイズ代わりに全文字数をチェックしておきましょう。
max_characters_instruction = df["instruction"].apply(lambda x: len(x)).max()
max_characters_output = df["output"].apply(lambda x: len(x)).max()
print(f"max characters (instruction): {max_characters_instruction}")
print(f"max characters (output): {max_characters_output}")
max characters (instruction): 10795
max characters (output): 5435
全文字数>実際のトークンサイズの関係なので、今回のFine-tuning用データの場合では、プロンプトもレスポンスもトークンサイズは問題ないようです。
それではこちらのデータを使ってJSONLを出力します。今回はsystemのロールは使わずに、userとmodelの2ロールだけでJSONを作成します。validation用のデータセット中のデータ点数は256点以下にする必要があります。
def reformat_gemini(data:pd.DataFrame, output_file_path:str):
# JSONLを作成
with open(output_file_path, 'w', encoding='utf-8') as f:
for index in range(len(data)):
json_data = {
"messages": [
# {"role": "system", "content": system_prompt}, #今回はsystemは含めないのでコメントアウト
{"role": "user", "content": data.iloc[index]["instruction"]},
{"role": "model", "content": data.iloc[index]["output"]}
]
}
f.write(json.dumps(json_data, ensure_ascii=False) + "\n") # ensure_ascii=False を追加
df_train_valid = df.sample(frac=0.9, random_state=4519)
df_test = df.drop(df_train_valid.index)
df_valid = df_train_valid.sample(n=256, random_state=4519)
df_train = df_train_valid.drop(df_valid.index)
reformat_gemini(df, "example_data/gozaru-gemini.jsonl")
reformat_gemini(df_train, "example_data/gozaru-gemini-train.jsonl")
reformat_gemini(df_test, "example_data/gozaru-gemini-test.jsonl")
reformat_gemini(df_valid, "example_data/gozaru-gemini-valid.jsonl")
これで学習用データセットの準備は整いました。

ファインチューニング実行用に、作成したjsonファイルをGoogle Cloud Storageにアップロードします。
(terminal)
gcloud storage buckets create gs://gemini-sft-data --location=asia-northeast1
gcloud storage cp example_data/gozaru-gemini-train.jsonl gs://gemini-sft-data/gozaru/
gcloud storage cp example_data/gozaru-gemini-valid.jsonl gs://gemini-sft-data/gozaru/2. ファインチューニングの実行
学習用データセットが準備できれば、ファインチューニングの実行は簡単です。
REGION="asia-northeast1"
PROJECT_ID="chugai-llm-project"
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/tuningJobs \
-d '{
"baseModel": "gemini-1.0-pro-002",
"supervisedTuningSpec" : {
"training_dataset_uri": "gs://gemini-sft-data/gozaru/gozaru-gemini-train.jsonl",
"validation_dataset_uri": "gs://gemini-sft-data/gozaru/gozaru-gemini-valid.jsonl"
},
}'
3. 学習結果の確認
学習が成功するとVertexAI上からチューニング済みモデルを選択できるようになります。今回のござるデータセットを使った例も上手くチューニングできてるようで、ござる口調になってるのがわかります。

医療用LLM「Med-LM」を日本初採用
中外製薬は、医療用LLMである「Med-LM」を日本初採用し、創薬プロセスの革新を目指しています。Med-LMは、医療業界向けに微調整された基盤モデルであり高度な医学知識を備え、複雑な医療文書の内容を理解し、質問に答えたり、洞察をまとめたりすることができます。治験文書の処理や臨床試験計画の作成を効率化し、ドラッグラグ・ロスの解消や、新薬開発のスピードアップに貢献すると期待されています。
Med-LMで日本の医師国家試験に挑む
Med-LMはアメリカの医師国家試験 (USMLE) 形式の質問に回答し、人間の専門家レベルに到達した最初のAIシステムとして有名です。現行モデルのMedLM-LargeやMedLM-mediumは論文発表時のMed-PaLM (https://sites.research.google/med-palm/) をベースに更なる改良や学習がされているようです。
では、日本の医師国家試験 ではどうでしょうか?問題と解答が公開されている、令和5年2月に実施された第117回医師国家試験問題で試してみます。
問A001

多肢選択問題ですが、見事正解。
問E033
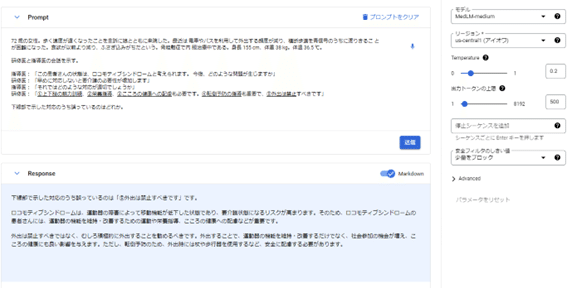
長文問題ですが、⑤で正解です。
一部の問題での検証になりますが、日本の医師国家試験でも正確な答えが得られそうです。
データサイエンティストお薦めのMed-LMの使い方
Med-LMは医療に特化したLLMであり、製薬企業で働くデータサイエンティストにとっても、頼もしい相棒です。例えば、私のように他業界からキャリア採用で入ったデータサイエンティストは、医学や疾患ドメインへの理解がなかなか追い付かず、初見のデータに遭遇した際に困ることも多々あります。そんな時にお薦めなのが、Med-LMに質問を投げかけて、データの理解と前処理・特徴量加工などのアドバイスをもらう事です。
ここでは、デジタルバイオマーカーのデータ解析を考えてみましょう。systoという変数名で “収縮期のデータ” と説明されてデータを受領しました。実際、初見時は何の収縮時刻?とよくわかりませんでしたが、Med-LMに聞くと即答で教えてくれます。

なるほど、心臓の収縮時刻ですね。1分辺りの収縮期回数 (60~100回/分) に基づいてデータの前処理も組めそうです。
医学データの理解や解析方針の検討以外にも、論文などの医学に関するテキスト文章を直接解析することもMed-LMは得意としています。ここでは例にキーワードと要約を試してみます。
以前に徳山が noteに執筆したデジパソ記事を使います。

キーワードの抽出と分類ラベル付与、要約も見事に行ってくれます。医学系のテキストを読み込ませると、疾患の種類や組織などに基づいてキーワードを抽出したり、分類に使えたりできそうです。
今後の展望、ヘルスケア企業のデータサイエンティストとして貢献
2024年5月にはGoogleの開発する最新のLLMであるGeminiをベースに構築されたMed-Geminiについても発表されており、Web検索と組み合わせた回答生成や、マルチモーダルの対話システムへの対応などが報告されています 。ますます楽しみな技術ですね。個人的にはDeepMindの動画生成AIであるVeoもとても注目しています 。いずれのモデルも早く使ってみたいです
創薬研究においては、LLMを用いて論文や特許などの膨大なデータを分析することで、新たな創薬ターゲットの発見や既存薬の新たな用途の発見に貢献したり、化合物や抗原情報を入力可能なマルチモーダルLLMを開発することで、in silicoでの分子設計や抗原との相互作用評価に用いることのできるAIアプリケーションの実装を行って行きたいと考えています。また、新医薬品の承認申請時に必要な申請書や添付文書などのコモン・テクニカル・ドキュメントのLLMによる簡易作成にも取り組んでいきたいと思います。