

【技術ブログ】機械学習と因果推論モデルを組み合わせリアルワールドデータから疾患リスクを評価。インターンシップを経て入社したデータサイエンスグループ新卒社員が解説

こんにちは、中外製薬のデジタル戦略推進部データサイエンスグループの水谷圭佑です。データサイエンスグループでは毎年インターンシップを受け入れており、約2カ月間にわたって1つのテーマに取り組みます。2年前の2022年夏のインターンシップで私がインターン生として取り組んだテーマを論文にして情報科学技術フォーラム(FIT)に投稿していたのですが、このたび、論文の共著の塚田啓介、徳山健斗(デジタル戦略推進部データサイエンスグループ)と共に、情報科学技術フォーラム(FIT)2024年次大会で論文賞を受賞することができました。大規模な医療データと機械学習を利用し、因果推論の枠組みで疾患リスクを評価する新規性が、受賞のポイントだったのでは?と考えています。今回のnoteでは、論文のテーマ「X-Learner を用いた抗がん剤治療による間質性肺疾患誘引リスクの評価」について解説します。

中外製薬デジタル戦略推進部データサイエンスグループ所属2024年入社。学部時代は機械学習、数理最適化を専門とする研究室で、タンパク質言語モデルを取り扱う研究に従事。データ解析コンペティションなどに参加するなか、2022年に開催した「中外データサイエンスインターンシップ」に挑戦。現在はデジタル戦略推進部データサイエンスグループに所属。
データサイエンスインターンの記事はこちら

学会中、個人的に面白かったなと感じたのはトップカンファレンスの紹介セッションです。こちらは、機械学習系のトップカンファレンスに採択された論文の著者本人が自ら論文の内容を解説していただくセッションで、とてもレベルの高い研究に触れることができました。
また、製薬企業の社員としてバイオインフォマティクスも聞いておかねばと思い、バイオインフォマティクスのセッションにも参加しました。今年に入り、Alpha Fold 3さらには先日Alpha Proteoが発表されタンパク質の立体構造予測の進化は著しいですね。
(10/8現在、Alpha Proteoは手法公開されていないですが。。)
それでは、今回の研究についてご紹介したいと思います。
X-Learner を用いた抗がん剤治療による間質性肺疾患誘引リスクの評価とは
がん治療における副作用の問題は、患者さんの生活の質に大きく影響を与える重要な課題です。今回は、肺がん治療における重大な副作用の一つ、間質性肺疾患(ILD)に焦点を当てます。この副作用は、肺がんの治療の継続を困難にする可能性があり、患者さんと医療現場に大きな負担をもたらしています。従来、このような副作用リスクを評価するには大規模な臨床試験が必要でした。しかし、コストや時間の問題から、副作用だけを対象とした試験の実施は容易ではありません。そこで注目されているのが、匿名化された電子カルテデータの活用です。
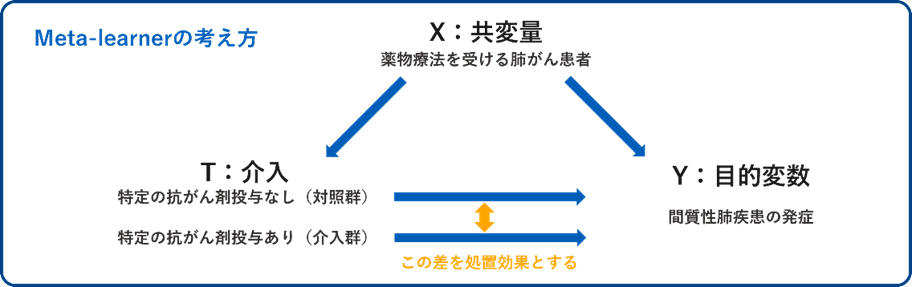
この研究では、匿名化された肺がん患者の大規模電子カルテデータを用いて、抗がん剤治療によるILDの発症リスクを評価しています。今回は、Meta-Learnerという因果推論の手法を用いることにしました。Meta-Learnerは因果推論に機械学習を応用し、介入の条件付き平均処置効果(CATE)を推定する手法です。
Meta-Learnerの代表的なモデルには、対照群と介入群を同一のモデルで学習して処置効果を推定するS-Learner、対照群と介入群で別々のモデルを学習して処置効果を推定するT-Learner、T-Learnerに傾向スコアを導入することで対称群と介入群のデータ数の不均衡性を考慮するX-Learnerがあります。
本研究では、選択バイアスを考慮しながら介入効果を推定できることから、X-Learnerを採用し、抗がん剤の種類ごとにILD発症への影響を評価しています。
X-Learnerの各ステップではLightGBMを使用し、ILD発症予測モデルや抗がん剤投与予測モデルを作成しました。これらのモデルを組み合わせることで、患者ごとの条件付き平均処置効果(CATE)を算出しています。
LightGBMの入力には患者の背景情報や検査値などを使用し、一定の精度(AUC 0.78)でILD発症を予測できることが示されました。この際に、精度向上のため交差検証を用いたハイパーパラメータチューニングを行っています。
結果として、抗がん剤の種類によってILD発症リスクが異なる可能性が示唆されました。また、リスクに関連する患者の特徴も抗がん剤の種類によって異なる傾向が見られました。
このように、機械学習と因果推論の手法を組み合わせて、リアルワールドデータに適応することでデータから新たな知見が得られる可能性を示しています。ただし、モデルの精度にはまだ改善の余地があり、厳密な介入効果を見るためにはさらなる研究が必要だと思われます。
今回の研究では、モデルの構築よりもデータの前処理に時間をかけたなという印象があります。特に電子カルテの検査値データなどは、単位変換や項目選択、名寄せなど、追加のデータエンジニアリングを行う必要がありました。一方で、リアルワールドデータはデータ量やデータの種類が豊富であるため、データ解析を行う人間としてはとてもやりがいのある題材でした。このようなデータを取り扱えることも、製薬企業ならではの魅力かなと感じています。
現在、私は業務としてLLM(大規模言語モデル)を用いたシステム開発を行っており、実際のビジネス課題解決に応用しています。また、Google CloudやAWSなどのクラウドプラットフォームを利用して、データ解析や予測モデルの構築も行っています。
製薬企業でデータサイエンスに触れるようになって、LLMの社内利活用、バイオインフォマティクスを用いた創薬の効率化など残された課題はまだたくさんあるなと感じています。これらの課題解決に私たちと一緒に取り組んでみたい、データサイエンスと創薬の両方に興味があり新しい技術やアプローチを学ぶ意欲のある方は、ぜひインターンシップやキャリア採用にチャレンジいただければと思います。
あわせて読みたい
中外製薬のデータサイエンティストに関する記事
データサイエンティストによる技術ブログ